
(1)要将系统中的算法调优。有可能一个算法浪费了一小部分时间,但由于数据量可能比较大,以至于整体上1秒的时间内可能浪费大量的时间。因此,算法的设计还是比较重要的。
(2)其次,就是调整系统中占用资源比较多、运算速度比较慢的那些spout和bolt。在进行topology设计时需要设计好每个bolt的并行度。对于运行速度比较慢的bolt,需要调大他们的并行度,是得更多的资源用到这些计算上面来。这里,bolt运行的快慢是可以从ui界面中看到的,如下图:
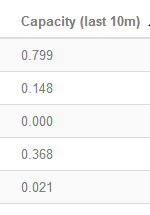
如上图,其中,capacity表示一种容量,其实就是占用的资源的百分比。比如,0.799就表示占用了79.9%的分配给这个bolt的资源。这个数值越大,则表示的处理起来速度越慢,则更要加大它的并行度。
(3)然后就是设置acker的数量。acker是在bolt成功处理后,进行ack调用的线程(还是进程,我忘记了)。当数据量比较大时,需要使用这个线程的次数就比较多,因此有可能这个线程就是制约处理速度的因素。因此,可以适当调大acker的数量,用于进行ack的调用。系统中,如果不设置的话,acker的数量默认为1;可以通过以下语句在topology中进行设定:
conf.put(Config.TOPOLOGY_ACKER_EXECUTORS, 10);//设置acker的数量
(4)当集群中数据量比较大时,则最好能设置spout中的等待处理的数据量的大小。当集群中等待的数据量比较大时,也就是数据发送比较快,但是处理太慢。这个时候应该阻止spout的发送,否则可能会导致系统队列爆掉。因此,设置以下:
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 10000);//设置一个spout task上面最多有多少个没有处理的tuple(没有ack/failed)回复,以防止tuple队列爆掉
(5)在Spout调用nextTuple方法时,如果没有emit tuple,那么默认需要休眠1ms,这个具体的策略是可配置的,因此可以根据自己的具体场景,进行设置,以达到合理利用cpu资源。
topology.spout.wait.strategy "backtype.storm.spout.SleepSpoutWaitStrategy"topology.sleep.spout.wait.strategy.time.ms 1